THE END OF THE RAINBOW
How do you find patient zero on the Internet?

In the light of the increasing interest in fake viral news, we thought of looking back at the “Epic Chain,” an online phenomenon that picked our interest three years ago. This event serves as a clear illustration of how the truthiness or political motivation of an individual piece of information has less of a relationship to its digital life than conventional wisdom would suggest. The Epic Chain carried no information whatsoever, nor served any purpose, yet it reached wide and fast. Epic Chain’s sole mission was to spread. At the same time, this seemingly random emergent phenomenon contained enough structure to address some fundamental questions about its origin, a fact of critical importance in today’s current analysis of fake news.
On February 11th, 2014 a singular event took place. At 6:42 AM @BenHowe perverted the retweet mechanism of Twitter by copy-pasting the URL of a tweet into a new message
“I’ll respond to this later. https://twitter.com/charlescwcooke/status/433249614431809536”
The original tweet by @charlescw-cooke, mentioned in the URL, was, in fact, a fake tweet. Either @charlescwcooke removed it or, most probably, @BenHowe altered the URL, so it linked to a non-existing tweet. Three minutes later, @redsteeze, one of @BenHowe’s 26.7K followers mimicked the odd retweeting mechanism by copying @BenHowe’s tweet URL into a new one
“I’ll be writing up a response to this @BenHowe tweet https://twitter.com/benhowe...”
The chain continued two minutes later with @LeonHWolf once again replicating the process, this time with @redsteeze‘s tweet URL
“Expect my rejoinder to this later this afternoon. https://twitter.com/redsteeze…”
Three minutes later, many people joined in:
“I am in the process of writing a devastating reply to this nonsense: https://twitter.com/LeonHW…”
“Oh, THIS cannot be allowed to remain unaddressed: https://twitter.com/Popehat…”
“I think I’m just going to accept this uncritically. https://twitter.com/moelane…”
“When the dust settles on this, I’m going to write 5000 words about the whole thing. https://twitt…”
“I imagine @AceofSpadesHQ will want to churn out a few thousand words on this topic. https://t…”
“I am offended. https://twitter.com/lachlan/status/433339253871742976”
“That’s it. @baseballcrank has finally gone off the rails. https://twitter.com/baseballcrank..”
“No. Just no. https://twitter.com/heminator…”
“I’m offended for everyone. https://twitter.com/sunnyright…”
By February 15th, 2014 at 7 AM, what became the “Epic Chain” comprised more than 6,700 tweets, each mentioning at least one other by the perverted mechanism began by @BenHowe.
Thousands of people joining a chain with no information or purpose — besides growing the chain itself. This event offers a unique case study to analyze an “empty digital epidemic.” While in many scenarios the real online seed is unclear and not every infection has an identifiable prior link, in the Epic Chain there is a well-known origin and each “infection” step is explicitly stated, providing a complete picture of its evolution.
As one can see in Figure 2, the Epic Chain began in a cluster of people with many followers. About 16 hours later, it reached a tipping point that drew thousands of new Twitter users in under 10 hours. After this initial success, the chain displayed little activity for about 20 hours and then underwent a second wave of about 1,000 new tweets in 5 hours. This scenario is typical of many epidemic processes, reaching a tipping point, dying out, reaching another susceptible community, and then enjoying a second wave of success.

What can we learn about a chain with no information or purpose? Can we, for instance, figure out who originated it? Or who was truly responsible for its spread? Is there enough structure in this absurd chain to ask questions of that nature? It could be the case that these empty cascades are fuelled by pure chaos, rendering them effectively unknowable. We hypothesize, on the contrary, that no matter how meaningless and purposeless, these chains have some idiosyncrasies that can be exploited to recover plenty of information.
When mentioning sources of information in a viral campaign, most people in an information cascade tend to mention their immediate local source (either by retweeting the original tweet, on Twitter, or in the more traditional “who said what” of gossip chains). However, a few explorers take the time and trouble to track back the origin of the information and end up mentioning what they consider to be the source. The existence of this information explorers and gatherers leave robust fingerprints in the form of time stamps around the origin that may be used to identify it, even in the absence of any useful clues.
As in every other epidemic in information cascades, people get infected as the wave moves across the network. Therefore susceptible nodes connected to an infected one tend to have similar infection times (with slight variations due to their peculiarities such as inter-tweet time in the case of Twitter). When we look at Figure 1, in which time is marked by color, we tend to see clusters of different sizes but similar colors. This is the case for every cluster but two of them: the one around the original @BenHowe’s tweet and the one around the fake original of @charlescwooke. Around these tweets, we find others with very different timestamps. Those belonging to information gatherers that were reached by the Epic Chain at various times but took the trouble to go back to the source to mention it. By doing so, they left their mark in two forms: a bigger cluster than expected (since the central node is surrounded by those directly infected by him plus those of the information gatherers) and a highly characteristic multi-colored pattern.
Similarly to in many other networks, Epic Chain users display a heavy-tailed distribution of some followers, and similarly to any other epidemic, highly connected nodes tend to infect more people than poorly connected ones. Hence another heavy-tailed distribution is expected when analyzing some mentions of each tweet. This can be seen in Figure 3 in which we also display the distribution of variation of neighbors infection times, measured as the standard deviation. The vertical dotted line of Figure 3 marks the point at which lies @BenHowe’s original tweet went out. It can be observed how this line moves to the right as we move from the follower’s distribution to the mentions one. As stated before, we expect the seed to have more neighbors than expected just by its number of followers. Moreover, then again to the right when we move to the variation of neighbors infection times (a consequence of the characteristic multi-colored cohort of nodes of Figure 1).

Therefore, three different factors are characteristic of the origin of an information epidemic: its earliest time of appearance, a higher ratio of mentions/followers, and a bigger variation in times of appearance of the nodes mentioning it as the source. This can be seen in Figure 4 in which we can observe that
- The real seed is among the most mentioned nodes (left column),
- While it has a mention/followers ratio above average (middle column) it’s hard to establish a difference based solely on this factor,
- The real seed is among the nodes with higher variation within the times in which it is mentioned (rightmost column).
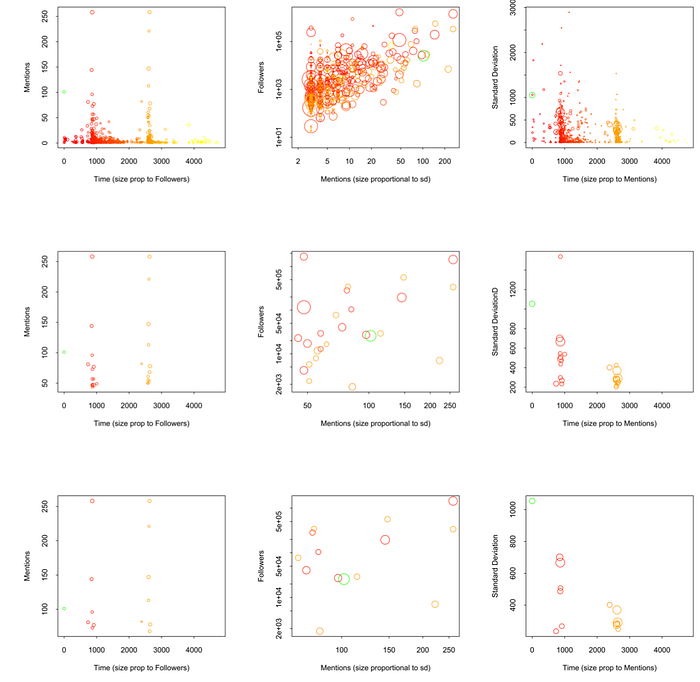
Nevertheless, nodes with few mentions might display a high variation in mention times not because they truly have it but because of the noise introduced by their few mentions. Once we filter out to only the most mentioned nodes (see a bottom right plot of Figure 4) the original seed (marked in green) stands out as the one among the most mentioned that has the biggest standard deviation in the times in which it is mentioned.
Twitter has the peculiarity of marking Retweets (RT) as mentions to the original Tweet. That is, a RT A of a tweet B which is a RT of a Tweet C is marked as a direct RT of the Tweet C. Therefore, in order to make sure that what we are observing is the digital footprint of information explorers and not a peculiarity of Twitter’s retweet system we eliminate from the chain all RT. The effect is not only not eliminated but slightly more clear as it can be seen in Figure 5.
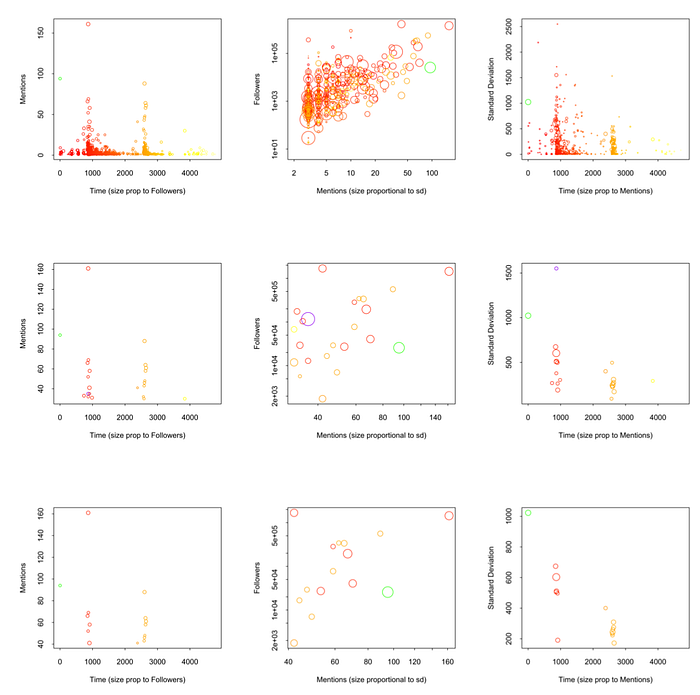
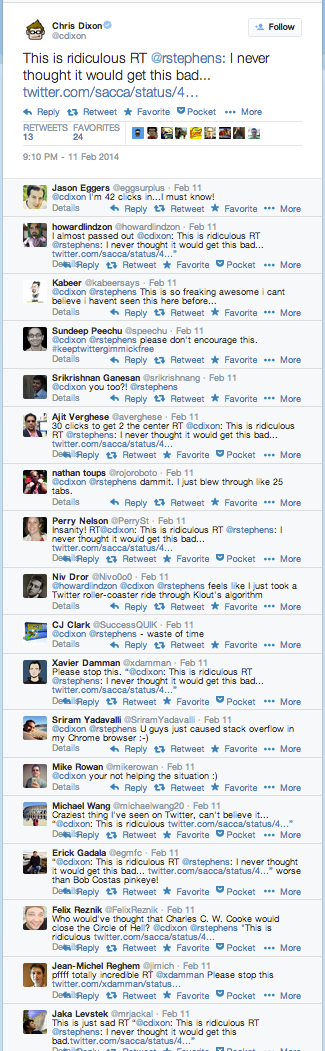
In Figure 5 we can also see how a possible “false origin” from @cdixon, marked in purple, displaying a high standard deviation in mention times has nevertheless a much smaller ratio mentions/followers plus an order of magnitude fewer mentions than the real seed from @BenHowe, marked in green. The different nature of their mentions becomes even clearer when we look at the comments left by other users to their respective tweets (see Figure 5). It can be readily seen that while comments to @cdixon’s tweet are mostly from the same day, comments on the original @BenHowe’s tweet span all over the chain period (Note: Twitter does not provide an API to retrieve such comments automatically).
This digital footprint, relying on a local structure, provides a robust mechanism to find the seed of an information cascade even in the absence of almost all data. In Figure 6 we can see a comparison of different algorithms to find the origin of an information cascade. From the most trivial “the tweet with the earliest timestamp” to “the tweet with the earliest mention”, “the tweet with more mentions”, “the tweet with the highest ratio mentions/followers” or the proposed “the tweet with the highest variation in mention times” (given that it has a significant number of mentions i.e. above a quarter of the number of mentions received by the most mentioned tweet).
All algorithms return a list of ordered nodes, being the top node the one with the highest score, for Figure 6d we took the top 3 nodes of each algorithm and show the distance to the real seed of the closest node to the real seed of these 3 top tentative seeds. Distance is expressed as the number of nodes in the network that are at the same or smaller distance to the real seed, that is, how close has the algorithm got to the actual seed regarding users that are closer to the true seed than the algorithm’s best candidate.
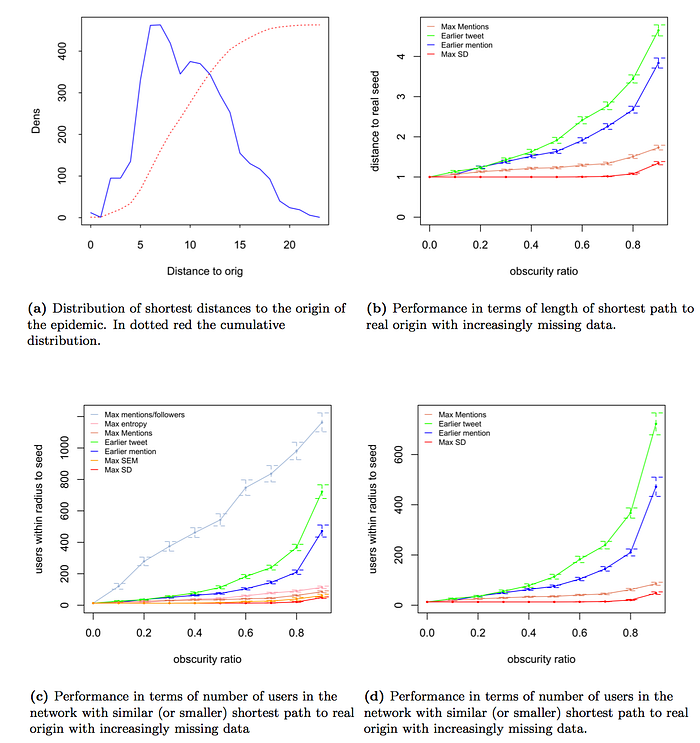
The analysis is repeated by randomly removing parts of the network (we call it obscurity ratio, how hard we make it for the algorithm to figure out the origin with fewer data, like a partial view of the network) up to a point in which we only consider 10% of the original network. For each obscurity ratio, the analysis is repeated 250 times for each algorithm for statistical significance. The “earlier tweet” and “earlier mention” approaches are easily affected by missing information since they go astray as soon as the real seed is one of the nodes eliminated. On the other hand, approaches that rely on a scale-free property such as “entropy of mentions times” or “number of mentions” display a much more robust behavior.
Surprisingly, a simple measure such as the Standard Deviation of the mentions times can retrieve the real seed all times up to 70% obscurity ratio and still maintains a perfect recovery of the real seed about 75% of the times with only 10% of the information available.
With help from simple algorithms, we found you, Mr. Ben Howe. After all, even empty chains contain enough structure to be knowable to statistical machinery, allowing us to find their “patient zero.” We can take solace in that, even though viral news cannot be stopped, their perpetrators may have a hard time hiding their hand.
